k8s
Kubernetes: What, When, Where & How — A Practical, Copy‑Paste Tutorial
This blog covers what Kubernetes is, when to use it, where it runs / where things live, and how to set it up & migrate from plain EC2 + Docker.
TL;DR
-
What: Kubernetes is a portable, extensible, open-source platform for managing containered workloads and services. It facilitates both declarative configuration and automation.
-
When: Use for multi-service apps, frequent deploys, autoscaling, and zero-downtime. Don’t use for tiny/simple stacks that a single VM + Docker Compose handles fine.
-
Where: On any Linux VMs (cloud/bare‑metal). Needs: container runtime (containerd), CNI (Flannel/Calico/Cilium), Ingress controller, Storage (CSI or local‑path), Registry for images, and a place to keep configs/secrets.
-
How: Start simple with K3s single‑node (fast) or go kubeadm multi‑node (production control). Migrate each service to a Deployment + Service + Ingress, move envs to ConfigMap/Secret, add probes, resources, and (optionally) HPA.
1) What: Core Concepts (fast but complete)
Kubernetes primitives
- Node: a VM/physical server in the cluster (e.g., an EC2 instance).
- Pod: the smallest deployable unit (usually 1 container). K8s schedules pods on nodes.
- Deployment: desired state for pods with rolling updates & self‑healing.
- Service: stable virtual IP/name to reach pods (ClusterIP/NodePort/LoadBalancer).
- Ingress: HTTP(S) routing from the Internet to Services (with an Ingress Controller like NGINX/Traefik).
- ConfigMap / Secret: configuration/env vars (Secret is base64‑encoded, use KMS/SealedSecrets for real security).
- Volume / PersistentVolume (PV) / PersistentVolumeClaim (PVC): stateful storage for pods.
- Namespace: logical isolation inside a cluster (e.g.,
dev,prod).
Kubernetes superpowers
- Self‑healing (restart pods), desired state (reconcile loops), rolling deploys/rollback, autoscaling, service discovery, resource quotas/limits, RBAC, observability hooks.
1.2 What we need to build Kubernetes cluster
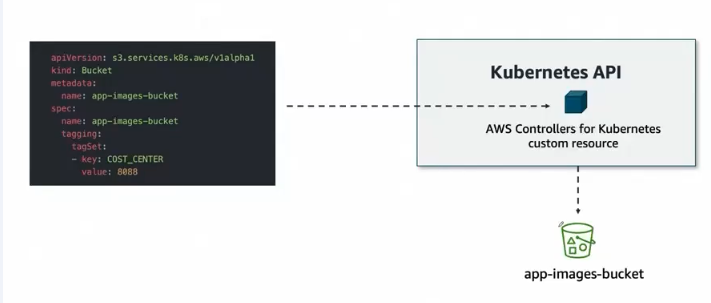
Sơ đồ trên mô tả AWS Load Balancer Controller integration với Kubernetes:
- YAML Manifest: Định nghĩa AWS Load Balancer resources (Bucket) trong Kubernetes
- Kubernetes API: Nhận và xử lý các custom resources từ AWS Controllers
- AWS Controllers for Kubernetes: Custom controllers quản lý AWS services từ trong K8s cluster
- app-images-bucket: S3 bucket được tạo và quản lý thông qua Kubernetes manifests
Đây là ví dụ về cách Kubernetes có thể quản lý cloud resources (AWS S3) thông qua custom controllers, không chỉ containers.
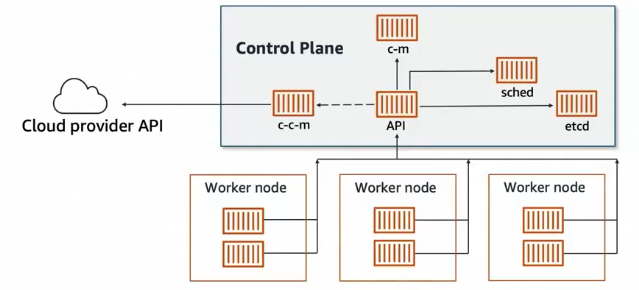
Kiến trúc Kubernetes Cluster gồm 2 phần chính:
- Control Plane: Bộ não của cluster, bao gồm:
- API Server: Điểm trung tâm nhận mọi request
- etcd: Database lưu trữ trạng thái cluster
- Scheduler: Quyết định pod chạy trên node nào
- Controller Manager: Đảm bảo trạng thái mong muốn được duy trì
- Worker Nodes: Nơi chạy các ứng dụng thực tế (containers)
- Cloud Provider API: Tích hợp với cloud services (AWS, GCP, Azure)

Hệ thống phân cấp và quản lý objects trong Kubernetes:
- Namespace: Cô lập logically các tài nguyên trong cluster (như "cluster trong cluster")
- Deployment: Workload resource mô tả desired state, không phải step-by-step instructions
- Pod: Đơn vị deployable nhỏ nhất, thường chứa 1 container (có thể nhiều container cho sidecar pattern)
- Container: Ứng dụng thực tế, với ephemeral files system
Bạn thường không tạo Pods trực tiếp - sử dụng Deployment để Kubernetes tự động tạo và quản lý Pods, đảm bảo desired state được duy trì.
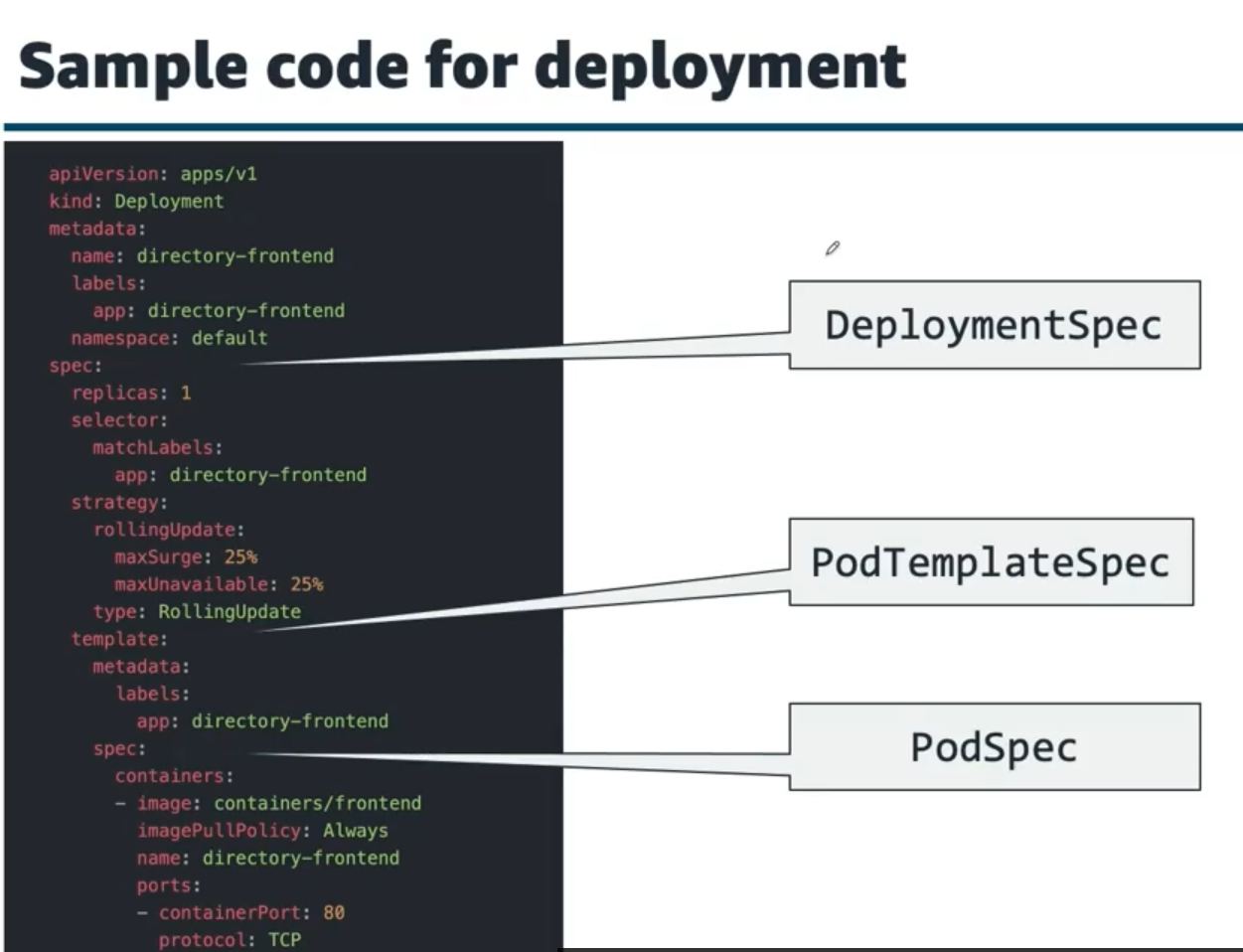
Cấu trúc Deployment YAML - Desired State Declaration:
- DeploymentSpec: Khai báo số replicas (horizontal scaling) và strategy cho updates
- PodTemplateSpec: Template mô tả cách tạo Pods, bao gồm labels (như app: directory-frontend)
- PodSpec: Chi tiết container configuration (image, ports, resources)
- Rolling Update Strategy: Chiến lược deploy tự động (maxSurge, maxUnavailable)
Deployment controllers sẽ liên tục monitor cluster state và tự động tạo/restart Pods để maintain desired state - không cần manual intervention.
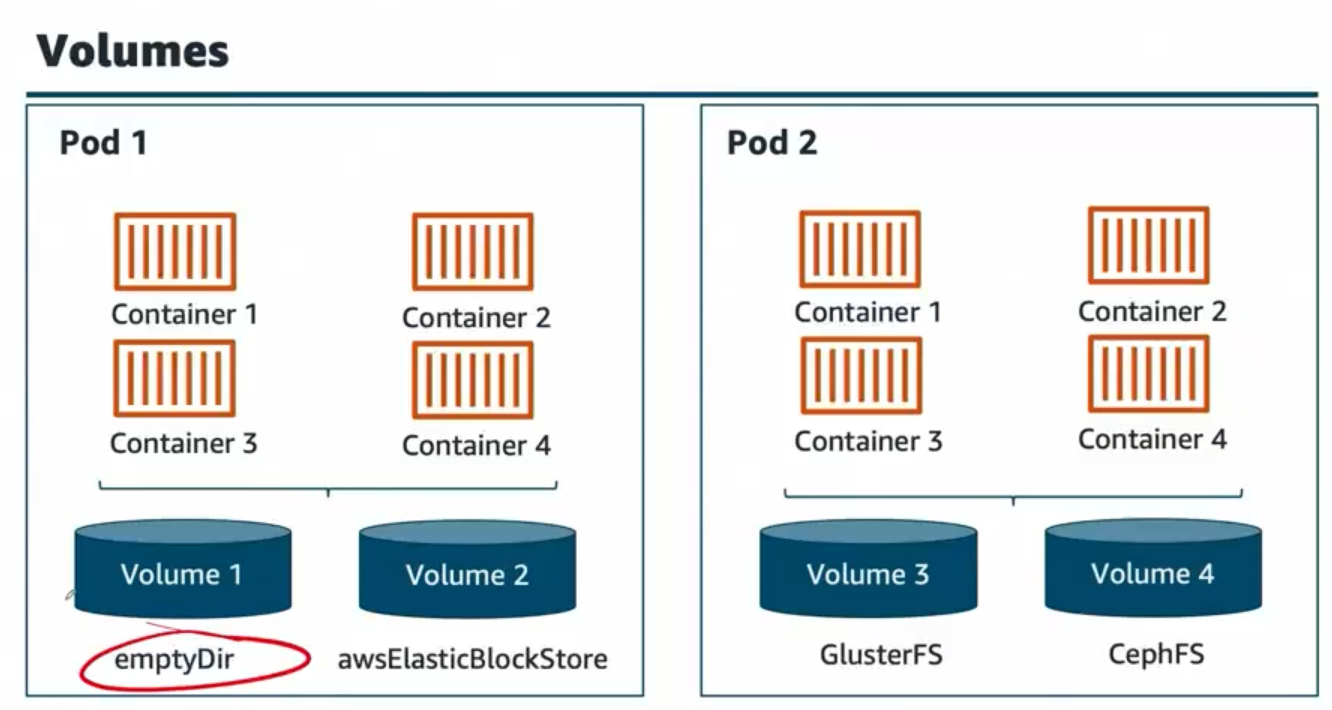
Hệ thống quản lý storage trong Kubernetes:
- Pod 1 & Pod 2: Các pods có thể chạy trên các nodes khác nhau nhưng vẫn truy cập được storage
- EmptyDir Volume: Storage tạm thời được tạo khi Pod khởi chạy, sẽ bị xóa khi Pod removed
- AWS ElasticBlockStore: EBS volumes cho persistent storage, không bị mất khi Pod restart
- GlusterFS & CephFS: Network file systems cho shared storage giữa multiple pods
Files trong Pod containers là ephemeral - khi container biến mất thì files cũng biến mất. Volumes giải quyết vấn đề này bằng cách cung cấp persistent storage.
2) When: Should You Use Kubernetes?
Use K8s when one or more of these is true:
- Applications have grown beyond CPU, network, storage requirements of a single node
- You have > 5 services (or expect to), and/or deploy frequently (≥ 5 times/week)
- Need zero‑downtime deploys, automatic recovery, blue‑green/canary
- Traffic spikes (flash sales, events) → want autoscaling
- Want to eliminate manual processes for scheduling containers, scaling, monitoring health
- Multiple teams → need standardized operations (RBAC, quotas, CI/CD)
- Multiple containers performing different tasks across multiple nodes
- Need fault-tolerance: node can fail, system detects and relaunches services
Avoid/Delay K8s when:
- 1–2 apps, steady traffic, rare deploys → Docker Compose + Nginx on a single VM is faster/cheaper
- Team lacks ops bandwidth: K8s adds operational complexity and you must run upgrades, monitoring, backups
Rule of thumb: Start simple; adopt K8s when release frequency, service count, fault-tolerance requirements, or SLA demands it.
3) Where: Runtime, Networking, Storage, Registry, Config
Where does K8s run?
- Anywhere with Linux VMs: cloud (EC2/GCE), bare‑metal, on‑prem, edge. You don’t have to use managed offerings (EKS/GKE/AKS) if you prefer DIY.
Where do my containers run?
- On nodes using a container runtime (usually containerd). K8s schedules pods across nodes.
Where do services get IPs?
- CNI plugin (Flannel/Calico/Cilium) provides Pod networking. Services get stable virtual IPs inside the cluster.
Where does inbound traffic enter?
- Via an Ingress Controller (NGINX/Traefik) listening on node ports/LB. Public DNS points to the controller.
Where is data stored?
- For stateful workloads: use CSI drivers (e.g., AWS EBS CSI) or simpler local‑path (single‑node dev). PVCs bind to PVs.
Where are images kept?
- A container registry: Docker Hub, GHCR, GitLab Registry, or AWS ECR. CI pushes images; K8s pulls them.
Where are configs/secrets?
- ConfigMap and Secret (optionally sealed/encrypted). Infrastructure configs live in Git (Helm/Kustomize).
4) How: Two Setup Paths
Path A — K3s (single‑node) — quickest way to get started
Good for dev/POC or small prod where a single VM is acceptable.
# Ubuntu VM (e.g., EC2) sudo apt-get update -y && sudo apt-get upgrade -y curl -sfL https://get.k3s.io | sh - # Kubeconfig for kubectl mkdir -p ~/.kube sudo cp /etc/rancher/k3s/k3s.yaml ~/.kube/config sudo chown $(id -u):$(id -g) ~/.kube/config # Verify kubectl get nodes kubectl get pods -A
By default, K3s brings Flannel (CNI), Traefik (Ingress), and local‑path storage. You can swap Traefik for NGINX Ingress if you prefer.
Path B — kubeadm (multi‑node) — minimal production topology
For 1 control‑plane + ≥1 worker. You manage all pieces.
# On all nodes: disable swap, prepare kernel modules sudo swapoff -a sudo sed -i '/ swap / s/^/#/' /etc/fstab cat <<'EOF' | sudo tee /etc/modules-load.d/k8s.conf overlay br_netfilter EOF sudo modprobe overlay && sudo modprobe br_netfilter cat <<'EOF' | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1 EOF sudo sysctl --system # Install containerd + kubeadm/kubelet/kubectl (Ubuntu; v1.30 as an example) # (omitted full repo setup for brevity; follow official docs for your distro) # On control-plane: sudo kubeadm init --pod-network-cidr=10.244.0.0/16 mkdir -p $HOME/.kube sudo cp /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config # Install a CNI (Flannel shown) kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml # On workers: join using the token/sha printed by kubeadm init sudo kubeadm join <CP_PRIVATE_IP>:6443 --token <token> --discovery-token-ca-cert-hash sha256:<hash>
Then install Ingress NGINX, MetalLB (if you want LoadBalancer type on bare VMs), metrics‑server, cert‑manager (TLS), and your storage solution (EBS CSI / OpenEBS / local‑path).
5) How: From EC2 + Docker → Kubernetes (Migration)
Step‑by‑step
-
Harden your images: add
/healthendpoint, small base images, properCMD, clear listening port. -
Move env/config:
- Non‑secrets → ConfigMap; secrets → Secret (optionally Sealed Secrets).
-
Model each service:
Deployment(replicas, probes, resources) +Service(ClusterIP) +Ingress.
-
Expose to the Internet: Ingress rule per host/path; point DNS to the Ingress entrypoint.
-
Add autoscaling: install metrics‑server, then
HorizontalPodAutoscaler. -
Cut over: run K8s side‑by‑side, route small % traffic (canary) or flip DNS; monitor logs/metrics; rollback quickly if needed.
Compose → K8s mapping
| Docker Compose | Kubernetes equivalent |
|---|---|
services.<name>.image | Deployment.spec.template.containers[].image |
ports: "80:3000" | Service (ClusterIP) + Ingress rules |
environment: | ConfigMap / Secret |
volumes: | PersistentVolumeClaim + VolumeMount |
depends_on: | |
| (usually handled by probes & readiness) |
Minimal manifests (example: one backend on port 3000)
apiVersion: v1 kind: Namespace metadata: { name: prod } --- apiVersion: v1 kind: ConfigMap metadata: { name: app-a-config, namespace: prod } data: NODE_ENV: "production" --- apiVersion: v1 kind: Secret metadata: { name: app-a-secret, namespace: prod } type: Opaque stringData: DATABASE_URL: "postgres://user:pass@host:5432/db" --- apiVersion: apps/v1 kind: Deployment metadata: { name: app-a, namespace: prod } spec: replicas: 2 selector: { matchLabels: { app: app-a } } template: metadata: { labels: { app: app-a } } spec: containers: - name: app-a image: ghcr.io/you/app-a:1.2.3 ports: [{ containerPort: 3000 }] envFrom: - configMapRef: { name: app-a-config } - secretRef: { name: app-a-secret } readinessProbe: httpGet: { path: /health, port: 3000 } initialDelaySeconds: 5 livenessProbe: httpGet: { path: /health, port: 3000 } initialDelaySeconds: 15 resources: requests: { cpu: "100m", memory: "128Mi" } limits: { cpu: "500m", memory: "512Mi" } --- apiVersion: v1 kind: Service metadata: { name: app-a, namespace: prod } spec: selector: { app: app-a } ports: [{ port: 80, targetPort: 3000 }] type: ClusterIP --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: apps namespace: prod annotations: nginx.ingress.kubernetes.io/ssl-redirect: "true" spec: ingressClassName: nginx # or traefik if using Traefik rules: - host: api.example.com http: paths: - path: /app-a pathType: Prefix backend: { service: { name: app-a, port: { number: 80 } } }
Autoscale
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: { name: app-a, namespace: prod } spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: app-a minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 60
6) Operating Checklist (Day‑2)
- Probes (liveness/readiness) for every service.
- Resources (requests/limits) to prevent noisy neighbors & enable HPA.
- TLS via cert‑manager + Let’s Encrypt.
- Observability: metrics‑server → HPA; Prometheus/Grafana for metrics; Loki/Promtail for logs.
- Backups: for any stateful storage/DB.
- Upgrades: plan for K8s version bumps and node OS patching.
- RBAC & Namespaces: enforce least privilege and quotas.
7) FAQ: Is it just scaling containers or EC2s?
- K8s scales pods (containers) first on the nodes you already have.
- When nodes run out of CPU/RAM, you add nodes (more EC2s). You can automate this with Cluster Autoscaler, but it requires extra setup on DIY clusters.
- Beyond scaling, K8s gives rolling updates, health management, service discovery, configuration, security, and visibility — the platform around your containers.
8) Troubleshooting Cheatsheet
# What’s running? kubectl get nodes kubectl get pods -A # Describe why a pod isn’t ready kubectl describe pod <name> -n <ns> # Inspect logs kubectl logs deploy/app-a -n prod kubectl logs pod/<pod-name> -n prod --previous # Port-forward to debug locally kubectl port-forward svc/app-a 8080:80 -n prod # Apply and diff manifests kubectl apply -f k8s/ kubectl diff -f k8s/ # Exec into a pod kubectl exec -it deploy/app-a -n prod -- sh
9) Next Steps / Where to go from here
- Use Helm or Kustomize to template manifests per env.
- Gate
/editoror internal tools behind an Ingress + auth. - Introduce GitOps (Argo CD/Flux) to reconcile from Git.
- If you outgrow single‑node: add workers (k3s agent) or move to kubeadm cluster.
You now have a practical mental model of Kubernetes (what/when/where/how) and a working migration path from plain EC2 + Docker.